Python ile bazı xml ve html dosyalarının verilerini çekip işleme sokmanız gerekebilir. Bu işlemi Python’da yaparken Request ve Beautiful Soup 4 kütüphanelerini kullanmanız gerekecektir. Bu iki kütüphaneyi projemize dahil ettikten sonra belirlediğimiz websitedeki verileri işlemeye hazır hale getirmemize yarar. Bu sayede yaptığımız programa bot adını verebiliriz.
İlk başta modülleri bilgisayarımıza kuralım.
Pip paket yöneticisi ile kurulum ve projeye dahil etme
pip install requestsRequest kütüphanesi kurduk.
pip install beautifulsoup4BeautifulSoup4 kütüphanesini kurduk. Artık projeye dahil edebiliriz.
import requests
from bs4 import BeautifulSoupÖrnek Websitesinden Veri Çekmek
Websitesine bağlanma
Şimdi bir websitesinin verilerini çekelim. Ben alışveriş sitesi olan hepsiburada.com üzerinden ilerleyeceğim.
import requests
from bs4 import BeautifulSoup
urunLink = "https://www.hepsiburada.com/iphone-se-64-gb-p-HBV00000SXR45"
site = requests.get(urunLink)
siteIcerigi = BeautifulSoup(site.content,"lxml")
print(str(siteIcerigi))#karakter dizisine isterseniz değişterebilirsiniz.
Parser seçimi ve kurulumu
Ayrıştıcı kütüphanesi seçerken altaki tabloyu kullanabilirsiniz.
lxml kütüphanesi için kurulum
pip install lxmlhtml5lib kütüphanesi için kurulum
pip install html5libParser Seçimi
| Parser(Ayrıştıcı) | Kullanımı | Avantajları | Dezavantajları |
| Python’nun HTML ayrıştırıcısı | BeautifulSoup(markup, “html.parser”) | – İyi hız – Hafif (lenient*) (Python 2.7.3 ve 3.2’den itibaren.) | lmxl kadar hızlı değil ve html5lib kadar hafif değil |
| lxml’in HTML ayrıştırıcısı | BeautifulSoup(markup, “lxml”) | – Çok hızlı – Hafif | Harici C bağımlılığı(External C dependency) |
| lxml’in xml ayrıştırıcısı | BeautifulSoup(markup, “lxml-xml”) BeautifulSoup(markup, “xml”) | – Çok hızlı – Şu anda desteklenen tek XML ayrıştırıcısı | Harici C bağımlılığı(External C dependency) |
| html5lib | BeautifulSoup(markup, “html5lib”) | – Son derece hafif – Sayfaları web tarayıcısında olduğu gibi ayrıştırır – Geçerli HTML5 oluşturur | – Çok yavaş – Harici Python bağımlılığı |
*lenient: hafif, yumuşak. Tam çeviri değil.
Sayfa İçerisinde Arama
find_all()
Tanımlama: find_all(name, attrs, recursive, string, limit, **kwargs)
Not: Fonksiyonun her bir parametresinin özelliklerini kendi dokümantasyonundan inceleyebilirsiniz.
siteIcerigi.find_all("title")Sayfadaki title elementini dizi halinde geri döndürür. BeautifulSoup4 örneğine bakalım.
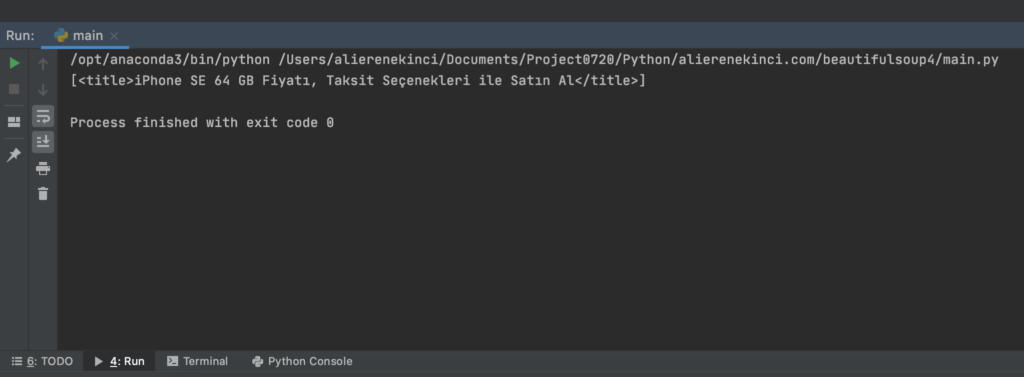
Sitede her zaman tek bir element olmayabilir. Bu durumda nasıl gözükecek bakalım.
siteIcerigi.find_all("a")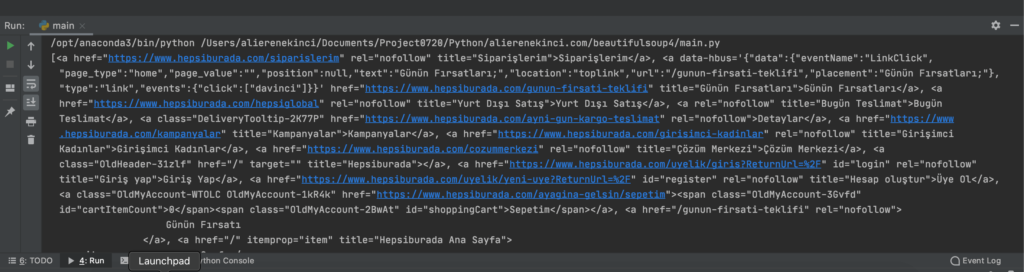
Gördümüz gibi karşımızda uzunca bir liste oluştu. Biz listenen a elementine aramayı daraltmak istiyorsak. Şu şekilde yapabiliriz.
Sayfada bulmak istediğimiz nesneyi belirledikten sonra onu incelemeye başlayabiliriz. Ben resimde görüldüğü gibi fiyatı çekmek istiyorum.
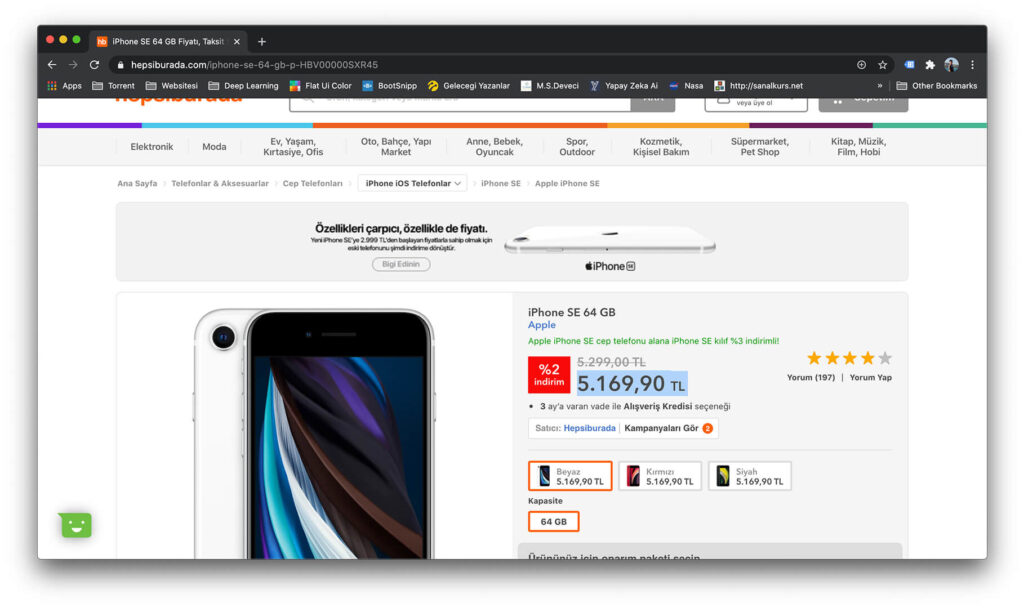
Daha sonra bu fiyat etiketinin hangi elemente olduğunu görmek için sağ tıklatıp sayfa kaynağını incele dememiz gerekmekte.
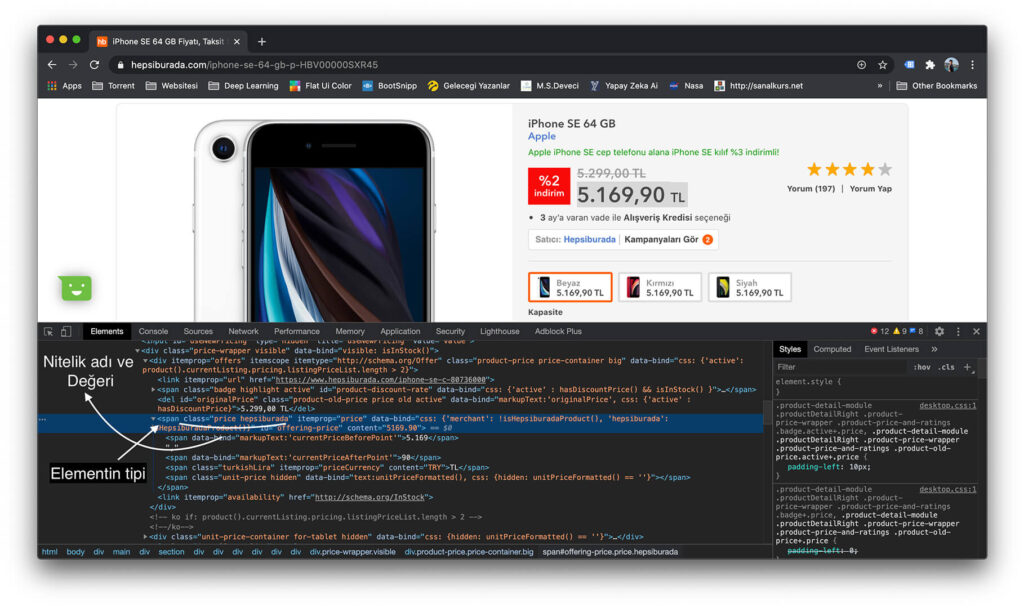
Sağ tık yapıp incelemek istediğimiz elementin bulup onu inceliyoruz. wikipedia.org dan aldığım görüntüye bakarak bir elementin yapısını anlayalım.

Bizde attrs kullanarak fiyat etiketinindeki değeri alacağız.
siteIcerigi.find_all("span", attrs={"class", "price"})Bu şekilde aratırsak bize dizi halinde dönen bir çıktı gelecektir.
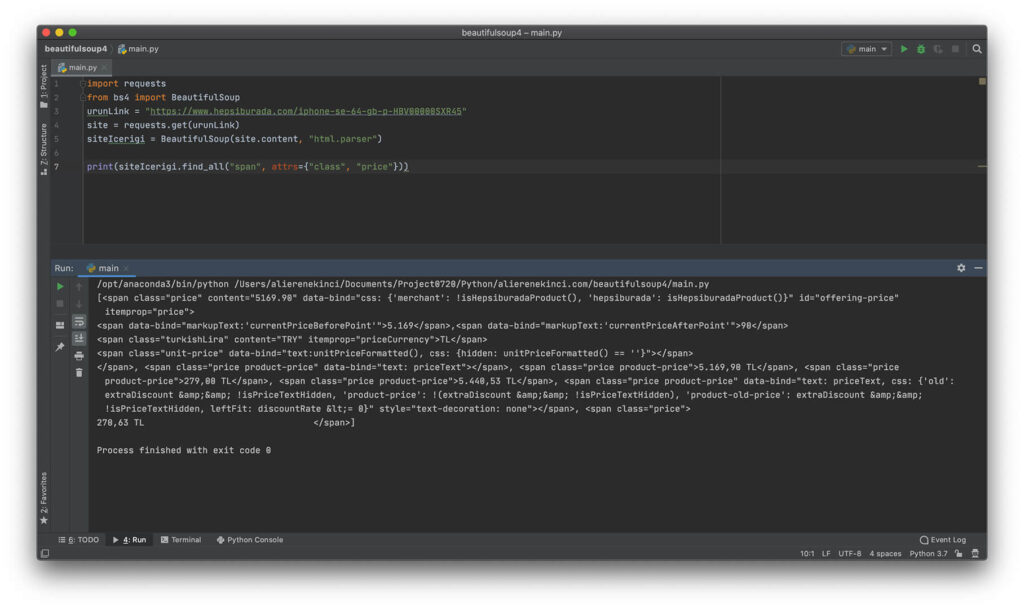
Döndürülen listenin ilk elemanına ulaşıp, string veri tipine dönüştürüp. Bu karakter dizisini baştan ve sondan elemanları silerek gerekli fiyatı alabiliriz. 13.08.2020 tarihinde hepsiburada.com üzerinde fiyat bilgilerine bu şekilde find_all() kullanarak bu şekilde ulaştım. İlerde sitenin teması değişebilir. Sizde farklı aksiyonlar kullanarak ulaşmanız gerekebilir.
import requests
from bs4 import BeautifulSoup
urunLink = "https://www.hepsiburada.com/iphone-se-64-gb-p-HBV00000SXR45"
site = requests.get(urunLink)
siteIcerigi = BeautifulSoup(site.content, "html.parser")
fiyatBilgisi = siteIcerigi.find_all("span", attrs={"class", "price"})
fiyatBilgisi = str(fiyatBilgisi[0])
print(fiyatBilgisi[29:36])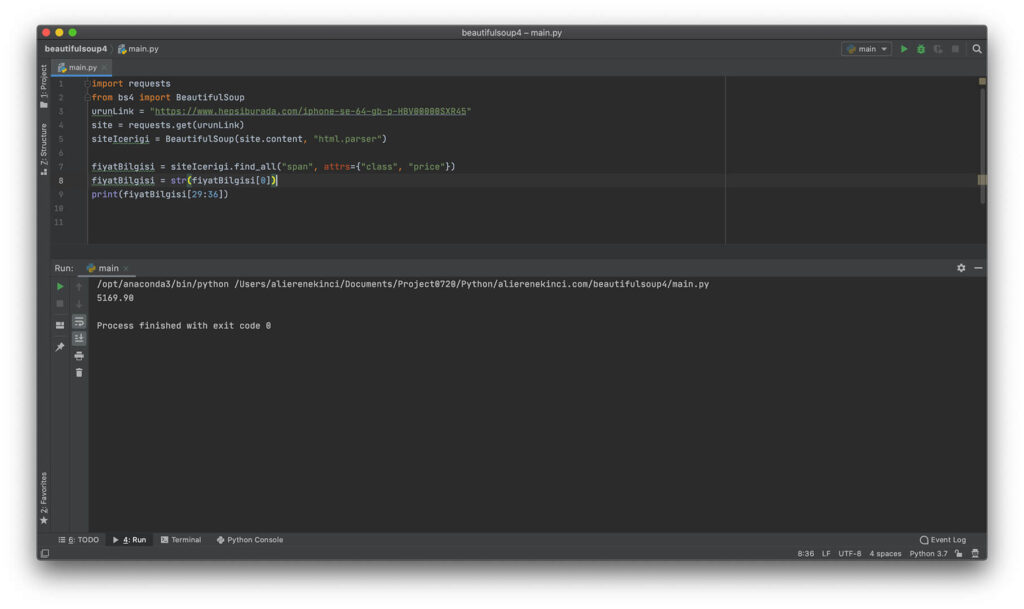
Eğer niteliğin değerini almak isteseydik .get kullanmamız gerekirdi. Yukardaki örnekte fiyat bilgisini span elementine nitelik olarak verilmiş. Şimdi get kullanarak fiyat bilgisini çekelim.
siteIcerigi.find_all("span", attrs={"class", "price"})[0].get("content")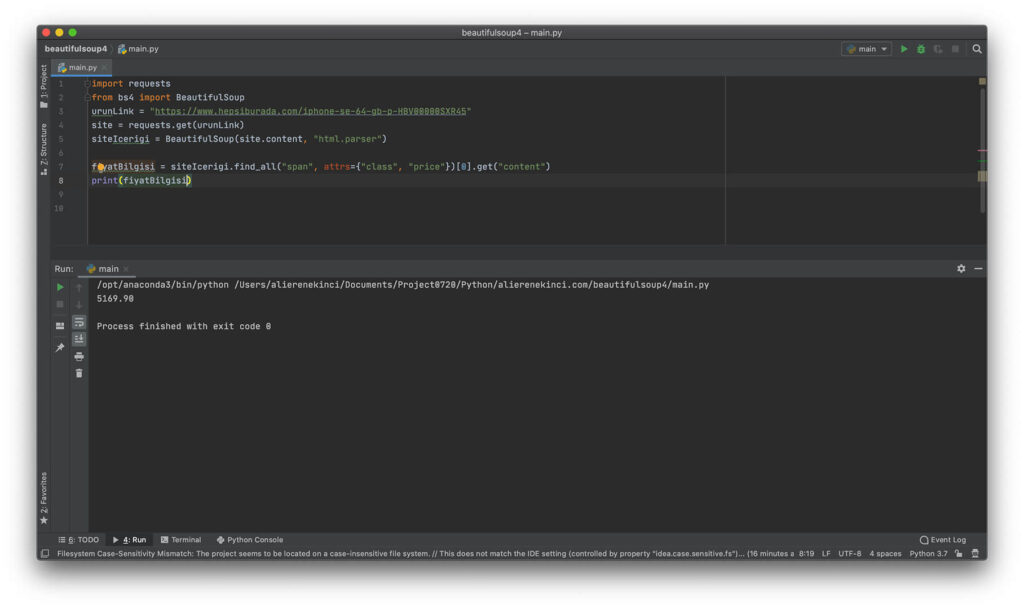
Burda [0] ile gösterilen kısım dizinin ilk elemanına ulaşmak içindi. get(“content”) yazarak nitelik olan content=”5169″ ‘nin değerini çekmemize yarıyor.
find()
Tanımlama: find(name, attrs, recursive, string, **kwargs)
Not: Fonksiyonun her bir parametresinin özelliklerini kendi dokümantasyonundan inceleyebilirsiniz.
find() aynı find_all() gibi çalışmaktadır. Ama find() ilk bulduğu değeri döndürmektedir. Mesela sayfada bir çok a elementi bulunabilir. Niteliklerinden a elementlerini kısıtlayabiliriz ama bize herzaman ilk olan element işimize yaramaya bilir.
siteIcerigi.find("span", attrs={"class", "price"}).get("content")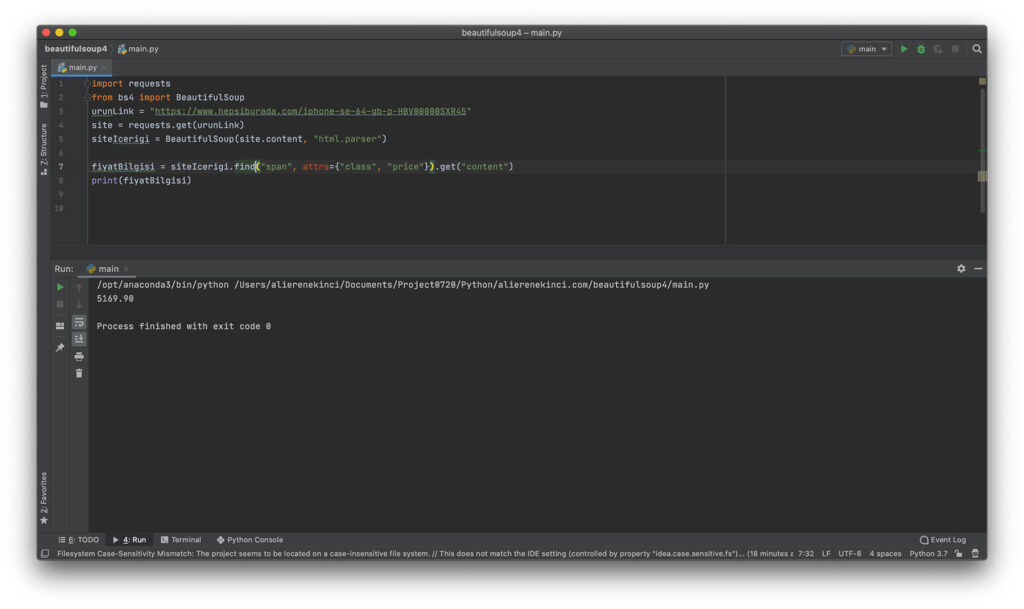
select()
Başka bir alternatif olan select() Beautiful Soup’a 4.7.0 dan sonra gelmiş. Css Selector nasıl kopyalayacağımıza bakalım önce.
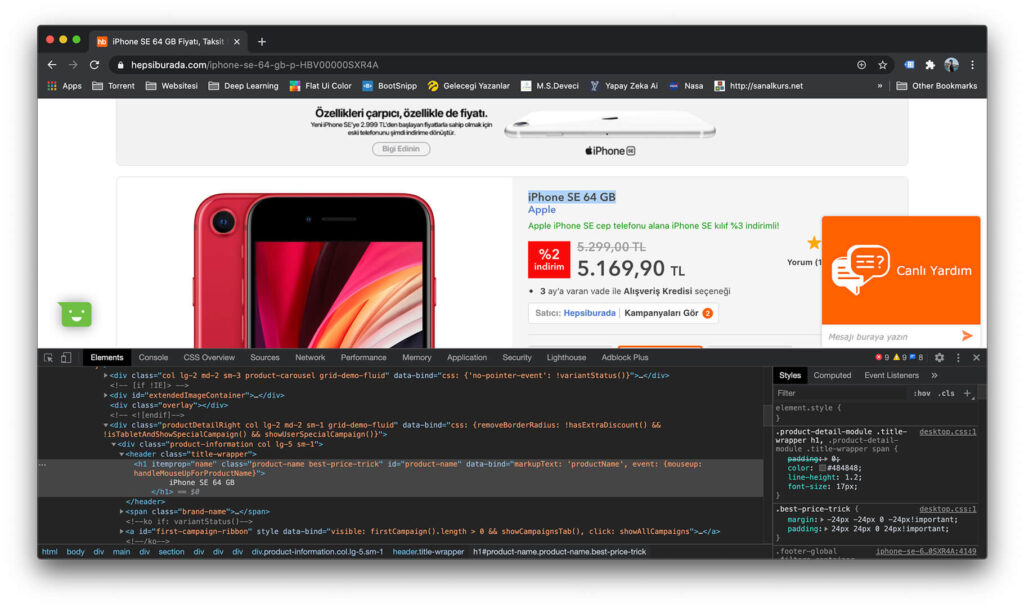
Burda ürünün ismini sağ tık yapıp incele dedik. Daha sonra beliren kısımdan sağ tıklarak css yolunu kopyalayalım.
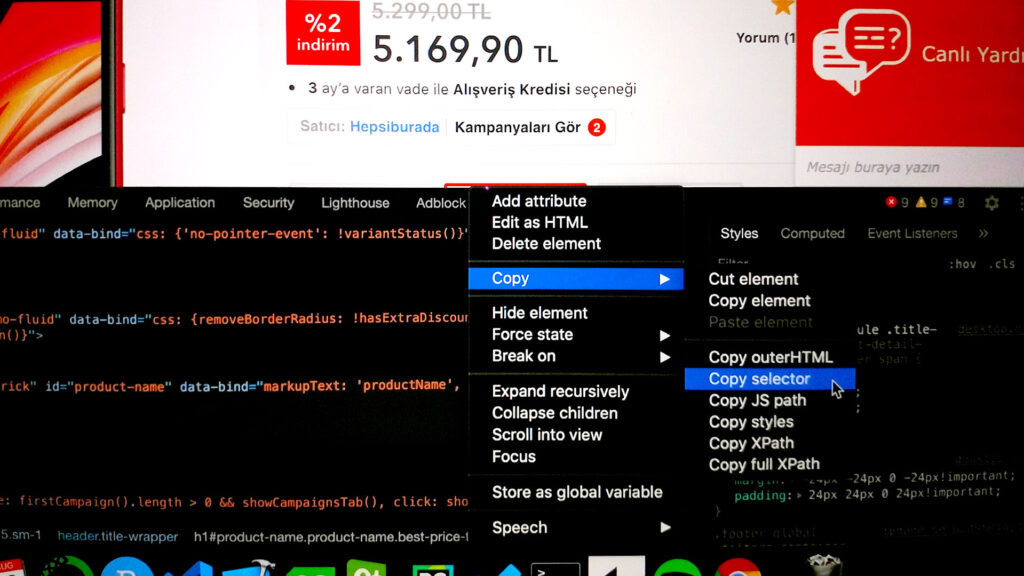
Şimdi select() ‘a parametre olarak yapıştıralım.
siteIcerigi.select("#product-name")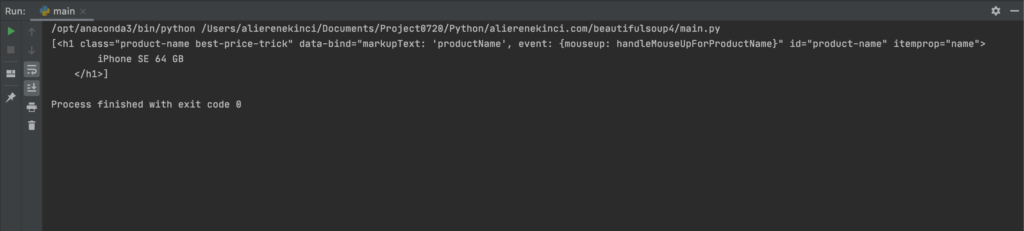
Css Selector kullanarak istediğiniz elementi seçebildik.
Evet sonunda buraya kadar geldin. Yazımı okuduğun için teşekkür ederim. Sorularını bana yorum kısmından iletebilirsin. Sağlıcakla kal.