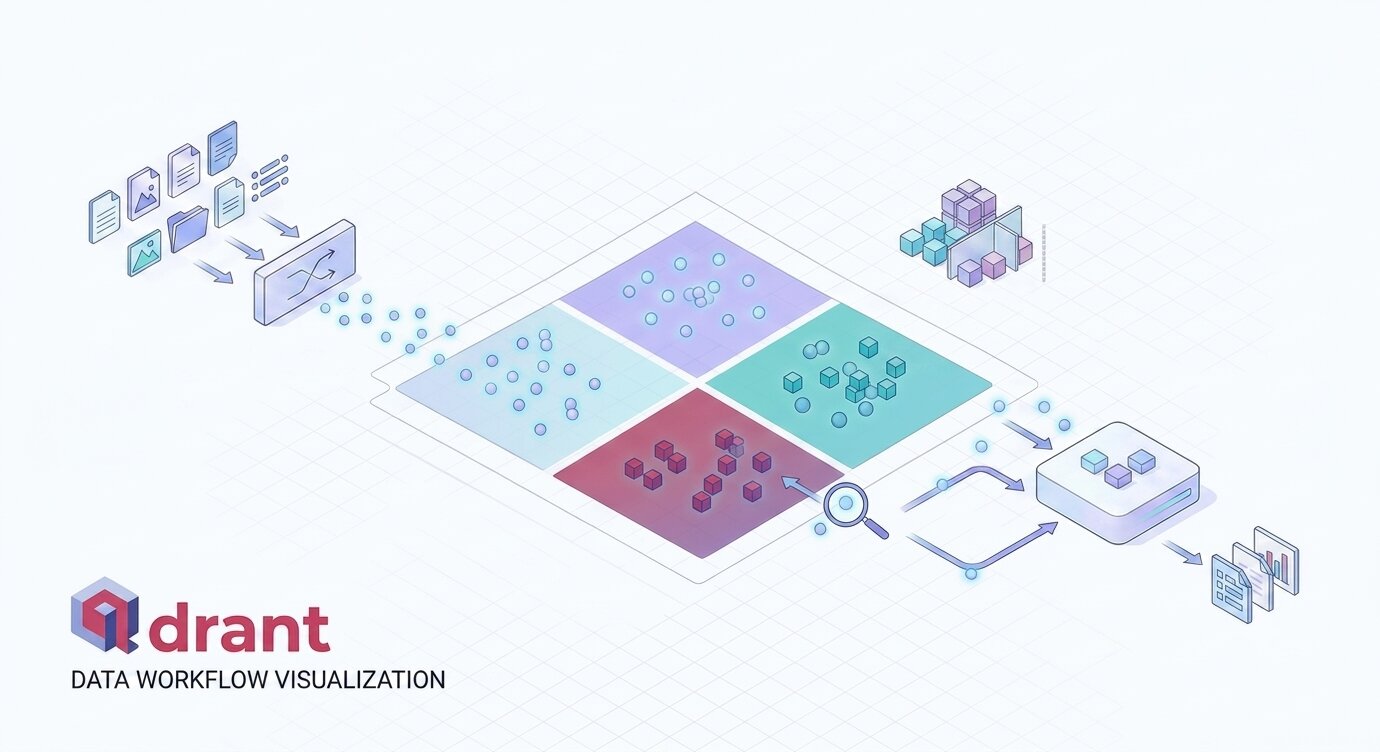
Büyük dil modelleri (LLM) tek başına güçlü araçlar olsa da gerçek uygulamalarda yalnızca eğitim verileriyle sınırlı kalırlar. “Şirketinizin belgelerinden doğru cevap vermesini, milyonlarca ürün arasından semantik arama yapmasını veya kullanıcıya kişiselleştirilmiş öneri sunmasını” istediğinizde devreye giren şey bir vektör veritabanıdır. Bu yazıda, yüksek performansı ve zengin filtreleme yetenekleriyle öne çıkan Qdrant‘ı baştan sona inceleyeceğiz.
Vektör Veritabanı Nedir?
Geleneksel veritabanları verileri tablo satırları veya JSON dokümanları olarak depolar ve tam eşleşme sorgularıyla iyi çalışır. Ancak “Bu cümleye anlamca en yakın 10 dokümanı getir” gibi bir sorguyu çözmeleri mümkün değildir.
Vektör veritabanları ise verileri Embedding adı verilen yüksek boyutlu sayısal diziler olarak depolar. Bir embedding modeli (OpenAI, Sentence Transformers, vb.) metni, görseli veya sesi sayısal bir vektöre dönüştürür. Anlamca benzer içerikler uzayda birbirine yakın vektörler üretir. Vektör veritabanları bu vektörler üzerinde Approximate Nearest Neighbor (ANN) algoritmaları kullanarak milisaniyeler içinde en yakın komşuları bulur.
Qdrant Nedir?
Qdrant (okunuşu: “quadrant”), Rust diliyle yazılmış açık kaynaklı bir vektör veritabanıdır. Özellikle şu alanlarda öne çıkar:
- Yüksek performans: Rust’ın bellek güvenliği ve düşük gecikme süresi.
- Zengin filtreleme: Vektör aramasını JSON payload filtreleriyle birleştirebilme.
- Hybrid search: Dense (yoğun) ve sparse (seyrek) vektörleri aynı anda kullanabilme.
- Discovery API: Pozitif ve negatif örneklere dayalı “keşif” aramaları yapabilme.
- Ölçeklenebilirlik: Dağıtık mimari (distributed deployment) desteği.
Kurulum
Python İstemcisi
pip install qdrant-client
Embedding üretmek için Qdrant ekibi tarafından geliştirilen ve daha hızlı/hafif olan FastEmbed kütüphanesini veya klasik Sentence Transformers’ı kurabilirsiniz:
# Hızlı ve hafif alternatif (Önerilen)
pip install fastembed
# Klasik alternatif
pip install sentence-transformers
Code language: PHP (php)Docker ile Qdrant Sunucusu
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
Code language: JavaScript (javascript)Kurulum sonrası http://localhost:6333/dashboard adresinden görsel arayüze erişebilirsiniz.
Temel Kullanım
Koleksiyon Oluşturma
[!WARNING] Boyut Uyuşmazlığı:
sizeparametresi, kullandığınız embedding modelinin çıktı boyutuyla tam olarak eşleşmelidir (örn. OpenAItext-embedding-3-smalliçin 1536,all-MiniLM-L6-v2için 384).
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient(host="localhost", port=6333)
client.create_collection(
collection_name="makaleler",
vectors_config=VectorParams(
size=384, # Modele göre değişir
distance=Distance.COSINE # Benzerlik metriği
),
)
Code language: PHP (php)Veri Ekleme (Upsert)
from qdrant_client.models import PointStruct
from fastembed import TextEmbedding
# Model otomatik olarak 384 boyutlu vektör üretir
model = TextEmbedding()
makaleler = [
{"id": 1, "text": "Python ile veri analizi", "cat": "python"},
{"id": 2, "text": "LLM ile uygulama geliştirme", "cat": "llm"},
]
embeddings = list(model.embed([m["text"] for m in makaleler]))
client.upsert(
collection_name="makaleler",
points=[
PointStruct(
id=m["id"],
vector=vector.tolist(),
payload={"baslik": m["text"], "kategori": m["cat"]}
)
for m, vector in zip(makaleler, embeddings)
]
)
Code language: PHP (php)Gelişmiş Özellikler
1. Payload Filtreleme
Vektör aramasını meta veri filtreleriyle kısıtlayabilirsiniz:
from qdrant_client.models import Filter, FieldCondition, MatchValue
sonuclar = client.search(
collection_name="makaleler",
query_vector=embeddings[0].tolist(),
query_filter=Filter(
must=[FieldCondition(key="kategori", match=MatchValue(value="llm"))]
),
limit=5
)
Code language: JavaScript (javascript)2. Discovery API (Keşif Modu)
“Buna benzesin ama şuna benzemesin” dediğiniz senaryolar için kullanılır:
from qdrant_client.models import ContextExamplePair
sonuclar = client.discover(
collection_name="makaleler",
target=embeddings[0].tolist(), # Hedef vektör
context=[
ContextExamplePair(positive=1, negative=2) # 1 nolu id'ye benzesin, 2'ye benzemesin
],
limit=5
)
Code language: PHP (php)Pratik Örnek: RAG Sistemi
RAG (Retrieval-Augmented Generation) süreci şu şekilde işler:
graph TD
A[Belgeler] --> B[Embedding Modeli]
B --> C[Qdrant Vektör Veritabanı]
D[Kullanıcı Sorusu] --> E[Embedding Modeli]
E --> F[Qdrant Search]
C -.-> F
F --> G[İlgili Bağlam/Context]
G --> H[LLM - GPT-4o]
D --> H
H --> I[Cevap]
Code language: CSS (css)RAG Pipeline Kodu
from typing import List, Dict
from qdrant_client import QdrantClient
from fastembed import TextEmbedding
from openai import OpenAI
qdrant = QdrantClient(host="localhost", port=6333)
embed_model = TextEmbedding()
openai_client = OpenAI()
def rag_query(soru: str) -> str:
# 1. Soruyu vektöre çevir
sorgu_vektor = list(embed_model.embed([soru]))[0].tolist()
# 2. Qdrant'tan ilgili bağlamı getir
search_results = qdrant.search(
collection_name="bilgi_tabani",
query_vector=sorgu_vektor,
limit=3
)
baglam = "\n".join([res.payload["icerik"] for res in search_results])
# 3. LLM ile cevap üret
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"Bağlamı kullanarak yanıtla: {baglam}"},
{"role": "user", "content": soru}
]
)
return response.choices[0].message.content
Code language: PHP (php)Qdrant vs Diğerleri
| Özellik | Qdrant | ChromaDB | Pinecone | Weaviate |
|---|---|---|---|---|
| Dil | Rust | Python | Kapalı Kaynak | Go |
| Hız | Çok Yüksek | Orta | Yüksek | Yüksek |
| Hybrid Search | Var (Native) | Kısıtlı | Var | Var |
| Discovery API | Var | Yok | Yok | Yok |
| Deployment | Self-hosted/Cloud | Self-hosted/Cloud | Yalnızca Cloud | Self-hosted/Cloud |
Sonuç
Qdrant, özellikle performans ve esnek filtreleme ihtiyacı olan production sistemleri için idealdir. Rust tabanlı mimarisi sayesinde düşük gecikme süreleri sunarken, Discovery API gibi yenilikçi özellikleriyle arama deneyimini bir üst seviyeye taşır.
Başlangıç için FastEmbed ile in-memory modda denemeler yapabilir, ardından Docker ile yerel sunucunuza geçiş yapabilirsiniz.