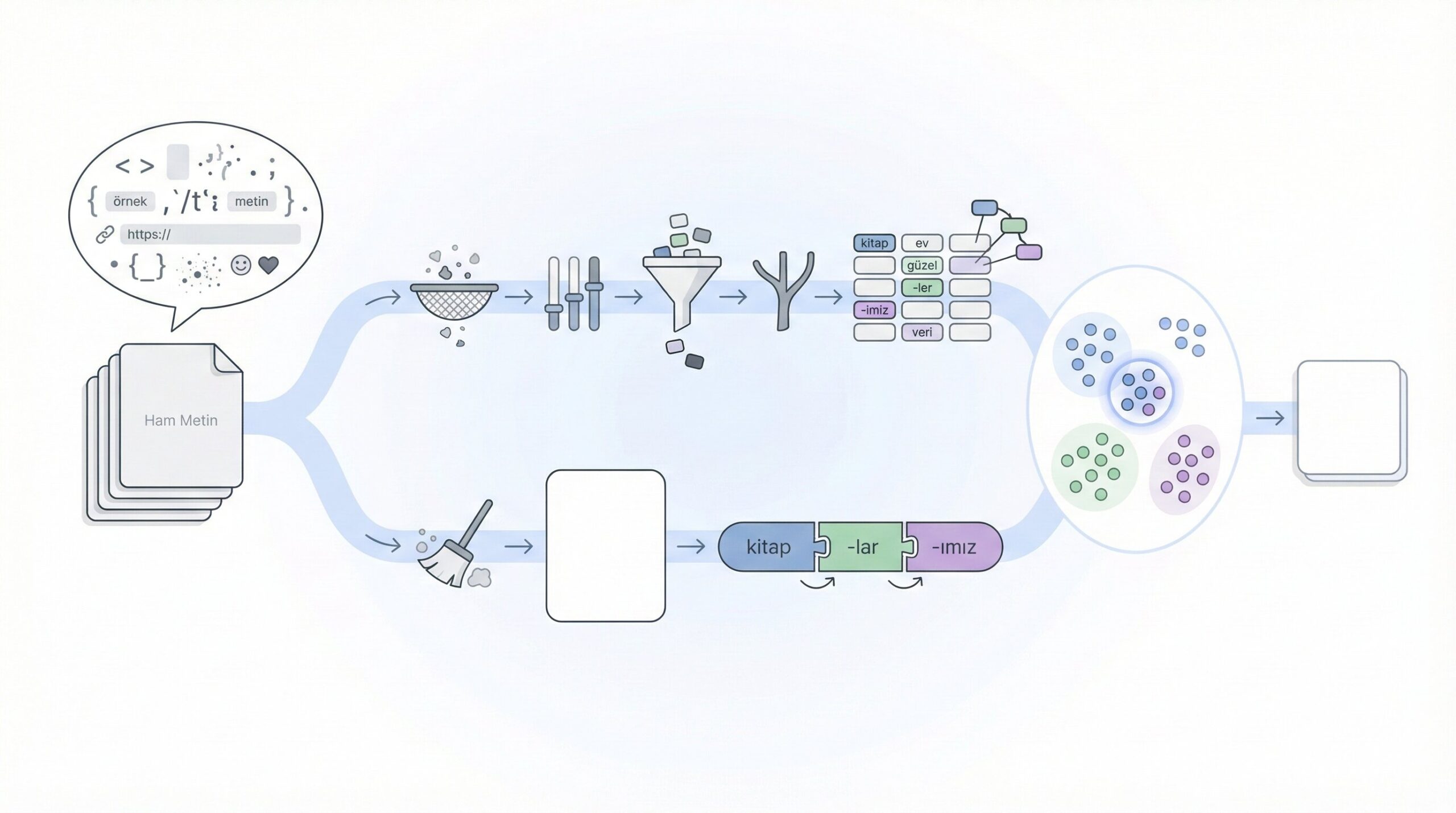
Doğal dil işleme projelerinde başarının anahtarı, metinlerin modellerin anlayabileceği bir forma dönüştürülmesinde yatar. Ham metin, yapılandırılmamış ve gürültülü bir veri türüdür — noktalama işaretleri, yazım hataları, emojiler, kısaltmalar ve dile özgü karmaşıklıklar içerir. NLP preprocessing, bu kaotik metin verisini anlamlı ve işlenebilir bir formata dönüştürme sürecidir.
Bu yazıda, klasik NLP preprocessing tekniklerinden modern transformer tabanlı yaklaşımlara kadar geniş bir yelpazede metin ön işleme adımlarını inceleyeceğiz.
Preprocessing Neden Bu Kadar Kritik?
NLP’de preprocessing’in önemi, seçilen model mimarisine göre değişir. Geleneksel makine öğrenimi modelleri (Naive Bayes, SVM, LDA) için kapsamlı preprocessing hayati önem taşırken, transformer tabanlı modeller minimal preprocessing ile çalışabilir. Ancak her iki durumda da veri kalitesi doğrudan model performansını etkiler.
Preprocessing’in temel amaçları şunlardır: gürültü azaltma yoluyla modelin gerçek sinyallere odaklanmasını sağlamak, vokabüler boyutunu kontrol altına alarak hesaplama maliyetini düşürmek, tutarlılık sağlayarak aynı kavramların farklı yazımlarını birleştirmek ve son olarak domain’e özgü adaptasyon ile modeli spesifik kullanım senaryolarına uyarlamak.
Klasik NLP Preprocessing Pipeline
1. Metin Temizleme (Text Cleaning)
Her NLP projesinin ilk adımı, metinden gürültüyü temizlemektir. Bu adım veri kaynağına göre özelleştirilmelidir.
HTML ve URL Temizliği:
Web scraping ile elde edilen veriler genellikle HTML tagları ve URL’ler içerir. Bu yapılar metin analizinde anlamsız gürültü oluşturur.
import re
from bs4 import BeautifulSoup
def clean_html_and_urls(text):
# HTML tag'lerini temizle
text = BeautifulSoup(text, "html.parser").get_text()
# URL'leri kaldır
text = re.sub(r'https?://\S+|www\.\S+', '', text)
# Email adreslerini kaldır
text = re.sub(r'\S+@\S+', '', text)
return text.strip()
Code language: PHP (php)Özel Karakter ve Noktalama İşaretleri:
Noktalama işaretlerinin tamamen kaldırılması her zaman doğru değildir. Sentiment analysis’de “!!!” veya “???” gibi tekrarlar duygu yoğunluğunu gösterebilir. Karar, görev tipine göre verilmelidir.
import string
def normalize_punctuation(text, remove_all=False):
if remove_all:
return text.translate(str.maketrans('', '', string.punctuation))
# Tekrarlayan noktalama işaretlerini normalize et
text = re.sub(r'([!?.]){2,}', r'\1', text)
# Fazla boşlukları temizle
text = re.sub(r'\s+', ' ', text)
return text.strip()
Code language: PHP (php)Emoji ve Emoticon İşleme:
Sosyal medya verilerinde emojiler önemli semantik bilgi taşır. Bu nedenle silmek yerine metne dönüştürmek daha iyi bir strateji olabilir.
import emoji
def process_emojis(text, strategy='demojize'):
if strategy == 'demojize':
# Emojiyi açıklamasına dönüştür: 😊 -> :smiling_face:
return emoji.demojize(text, language='tr')
elif strategy == 'remove':
return emoji.replace_emoji(text, replace='')
return text
# Örnek kullanım
text = "Bu ürün harika! 😊👍"
print(process_emojis(text)) # "Bu ürün harika! :gülümseyen_yüz::yukarı_bakan_başparmak:"
Code language: PHP (php)2. Metin Normalizasyonu
Küçük Harfe Dönüştürme (Lowercasing)
Büyük/küçük harf tutarsızlıklarını gidermek için standart bir adımdır. Ancak bazı durumlarda (NER, kısaltmalar) bilgi kaybına yol açabilir.
def smart_lowercase(text, preserve_acronyms=True):
if preserve_acronyms:
# Kısaltmaları koru (2+ büyük harf yan yana)
words = text.split()
processed = []
for word in words:
if not (len(word) >= 2 and word.isupper()):
word = word.lower()
processed.append(word)
return ' '.join(processed)
return text.lower()
# Örnek
text = "NLP ve AI teknolojileri hızla gelişiyor"
print(smart_lowercase(text)) # "NLP ve AI teknolojileri hızla gelişiyor"
Code language: PHP (php)Türkçe Karakter Normalizasyonu
Türkçe metinlerde sıkça karşılaşılan bir sorun, Türkçe karakterlerin ASCII eşdeğerleriyle karıştırılmasıdır.
def normalize_turkish_chars(text, to_ascii=False):
turkish_map = {
'ı': 'i', 'İ': 'I', 'ğ': 'g', 'Ğ': 'G',
'ü': 'u', 'Ü': 'U', 'ş': 's', 'Ş': 'S',
'ö': 'o', 'Ö': 'O', 'ç': 'c', 'Ç': 'C'
}
if to_ascii:
for tr_char, ascii_char in turkish_map.items():
text = text.replace(tr_char, ascii_char)
return text
Code language: PHP (php)Sayı İşleme
Sayıların nasıl işleneceği göreve bağlıdır. Topic modeling için genellikle kaldırılırken, NER veya bilgi çıkarımında korunabilir.
def process_numbers(text, strategy='remove'):
if strategy == 'remove':
return re.sub(r'\d+', '', text)
elif strategy == 'normalize':
return re.sub(r'\d+', '<NUM>', text)
elif strategy == 'keep':
return text
return text
Code language: JavaScript (javascript)3. Tokenization
Tokenization, metni daha küçük birimlere (token) ayırma işlemidir. Bu adım, preprocessing pipeline’ının en kritik kararlarından birini içerir.
Kelime Tabanlı Tokenization:
En basit yaklaşım boşluklardan ayırmaktır, ancak noktalama ve özel durumlar için yetersiz kalır.
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
# NLTK tokenizer (dil desteği sınırlı)
tokens = word_tokenize("Bu bir örnek cümledir.", language='turkish')
# Regex tabanlı tokenizer
def regex_tokenize(text):
# Kelime ve noktalama işaretlerini ayır
pattern = r"\w+|[^\w\s]"
return re.findall(pattern, text, re.UNICODE)
Code language: PHP (php)Türkçe İçin Gelişmiş Tokenization:
Türkçe gibi eklemeli (agglutinative) diller için özel tokenizer’lar gerekir. Zemberek ve TurkishNLP bu alanda güçlü araçlardır.
# Zemberek ile morfolojik analiz
from jpype import JClass, startJVM, getDefaultJVMPath
def setup_zemberek():
startJVM(getDefaultJVMPath(), '-ea',
'-Djava.class.path=zemberek-full.jar')
TurkishMorphology = JClass('zemberek.morphology.TurkishMorphology')
return TurkishMorphology.createWithDefaults()
# Alternatif: turkishnlp
from turkishnlp import detector
obj = detector.TurkishNLP()
obj.download()
obj.create_word_set()
Code language: PHP (php)4. Stop Words (Etkisiz Kelimeler) Kaldırma
Stop words, dilde sık geçen ancak semantik değer taşımayan kelimelerdir. Türkçe için “ve”, “bir”, “bu”, “ile” gibi kelimeler bu kategoridedir.
from nltk.corpus import stopwords
# NLTK Türkçe stop words
nltk.download('stopwords')
turkish_stopwords = set(stopwords.words('turkish'))
# Özelleştirilmiş stop words listesi
custom_stopwords = turkish_stopwords.union({
'falan', 'filan', 'ayrıca', 'ancak', 'bunun', 'şöyle', 'böyle'
})
def remove_stopwords(tokens, stop_set):
return [token for token in tokens if token.lower() not in stop_set]
Code language: PHP (php)Dikkat: Topic modeling gibi görevlerde stop words kaldırmak kritikken, transformer modelleri için genellikle gereksizdir — hatta zarar verebilir çünkü bu modeller bağlamı anlamak için bu kelimelere ihtiyaç duyar.
5. Stemming ve Lemmatization
Stemming, kelimelerin eklerini mekanik kurallarla kırparak köklerini bulur. Hızlıdır ancak her zaman geçerli kelimeler üretmez.
Lemmatization, kelimelerin sözlük formlarını (lemma) bulur. Daha yavaş ama daha doğrudur.
# Snowball Stemmer (Türkçe desteği sınırlı)
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer('porter') # Türkçe için ideal değil
# Türkçe için Zemberek lemmatization
def lemmatize_turkish(word, morphology):
analysis = morphology.analyze(word)
if analysis:
return analysis[0].getLemmas()[0]
return word
Code language: PHP (php)Türkçe için Pratik Yaklaşım:
Türkçe’nin karmaşık morfolojisi nedeniyle, Zemberek veya benzeri araçlar kullanılması önerilir. Alternatif olarak, subword tokenization (BPE) morfolojik zenginliği doğal olarak yakalar.
6. N-gram Oluşturma
N-gramlar, ardışık n token dizileridir. Kelime çiftleri (bigram) veya üçlüleri (trigram) bağlamsal bilgiyi yakalar.
from nltk import ngrams
from collections import Counter
def generate_ngrams(tokens, n=2):
return list(ngrams(tokens, n))
def get_common_ngrams(corpus_tokens, n=2, top_k=20):
all_ngrams = []
for tokens in corpus_tokens:
all_ngrams.extend(generate_ngrams(tokens, n))
return Counter(all_ngrams).most_common(top_k)
# Örnek kullanım
tokens = ["bu", "ürün", "çok", "güzel", "çok", "beğendim"]
bigrams = generate_ngrams(tokens, 2)
# [('bu', 'ürün'), ('ürün', 'çok'), ('çok', 'güzel'), ...]
Code language: PHP (php)Modern NLP Preprocessing: Subword Tokenization
Transformer çağında, preprocessing paradigması köklü bir değişim geçirdi. Modern modeller minimal preprocessing ile çalışır ve tokenization işini subword algoritmalara bırakır.
BPE (Byte Pair Encoding)
BPE, en sık görülen karakter çiftlerini iteratif olarak birleştirerek bir vokabüler oluşturur. GPT serisi bu yöntemi kullanır.
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# BPE tokenizer eğitimi
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
trainer = BpeTrainer(
special_tokens=["[UNK]", "[PAD]", "[CLS]", "[SEP]"],
vocab_size=32000,
min_frequency=2
)
# Corpus üzerinde eğit
tokenizer.train(files=["corpus.txt"], trainer=trainer)
# Kaydet ve kullan
tokenizer.save("turkish-bpe-tokenizer.json")
Code language: PHP (php)WordPiece
Google’ın BERT modelinde kullandığı yöntemdir. BPE’ye benzer ancak likelihood tabanlı birleştirme yapar.
from transformers import BertTokenizer, AutoTokenizer
# Önceden eğitilmiş Türkçe BERT tokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-cased")
text = "Doğal dil işleme çok heyecan verici bir alan."
tokens = tokenizer.tokenize(text)
# ['Doğal', 'dil', 'işleme', 'çok', 'heyecan', 'verici', 'bir', 'alan', '.']
# Token ID'leri
input_ids = tokenizer.encode(text)
Code language: PHP (php)SentencePiece
Google tarafından geliştirilen, dil agnostik bir tokenizer’dır. Özellikle Türkçe gibi eklemeli diller için etkilidir çünkü whitespace’e bağımlı değildir.
import sentencepiece as spm
# Model eğitimi
spm.SentencePieceTrainer.train(
input='corpus.txt',
model_prefix='turkish_sp',
vocab_size=32000,
character_coverage=0.9995,
model_type='unigram' # veya 'bpe'
)
# Kullanım
sp = spm.SentencePieceProcessor()
sp.load('turkish_sp.model')
tokens = sp.encode_as_pieces("Merhaba dünya!")
# ['▁Mer', 'haba', '▁dünya', '!']
Code language: PHP (php)Subword Tokenization’ın Avantajları
Bu yaklaşımların geleneksel yöntemlere göre önemli avantajları vardır. OOV (Out-of-Vocabulary) sorunu ortadan kalkar çünkü nadir kelimeler bile subword parçalarına ayrılabilir. Morfolojik zenginlik korunur, özellikle Türkçe gibi eklemeli dillerde ekler doğal olarak ayrı token’lar olur. Sabit vokabüler boyutu sayesinde bellek kullanımı optimize edilir. Ayrıca çok dilli modeller için ideal bir altyapı sunar.
Transformer Modelleri İçin Preprocessing
Modern transformer modelleri (BERT, GPT, T5) için preprocessing felsefesi şudur: “Mümkün olduğunca az müdahale et.”
Minimal Preprocessing Yaklaşımı
from transformers import AutoTokenizer, AutoModel
def preprocess_for_transformer(text, model_name="dbmdz/bert-base-turkish-cased"):
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Minimal temizlik
text = text.strip()
text = re.sub(r'\s+', ' ', text) # Fazla boşlukları normalize et
# Tokenize et
encoded = tokenizer(
text,
padding='max_length',
truncation=True,
max_length=512,
return_tensors='pt'
)
return encoded
Code language: PHP (php)Ne Zaman Ne Kadar Preprocessing?
Preprocessing derinliği, görev tipine ve model mimarisine göre belirlenmelidir.
Geleneksel ML modelleri (Naive Bayes, SVM, LDA) için kapsamlı preprocessing gerekir: lowercasing, stop words kaldırma, stemming/lemmatization, noktalama temizliği ve n-gram oluşturma önerilir.
Transformer modelleri (BERT, GPT) için minimal preprocessing yeterlidir: temel temizlik (HTML, URL), fazla boşluk normalizasyonu ve model-spesifik tokenizer kullanımı yeterlidir. Stop words, stemming ve lowercasing genellikle gereksizdir.
Hibrit yaklaşımlar için orta düzey preprocessing tercih edilir: domain-spesifik normalizasyon, özel tokenler ve isteğe bağlı lemmatization uygulanabilir.
Türkçe NLP için Özel Dikkat Noktaları
1. Eklemeli Dil Yapısı
Türkçe, tek bir kökten onlarca farklı form türetebilen eklemeli bir dildir. “Ev” kökünden “evlerimizden” gibi kompleks yapılar oluşur. Bu durum, kelime tabanlı yaklaşımlarda sparse representation sorununa yol açar.
Çözüm önerileri: Subword tokenization (BPE, SentencePiece) kullanmak, Zemberek ile morfolojik ayrıştırma yapmak veya karakter seviyesi modeller tercih etmek bu sorunu çözebilir.
2. Türkçe NLP Araçları
# Zemberek-NLP (Java tabanlı, en kapsamlı)
# https://github.com/ahmetaa/zemberek-nlp
# TurkishNLP (Python)
from turkishnlp import detector
nlp = detector.TurkishNLP()
# Stanza (Stanford NLP - Türkçe desteği var)
import stanza
stanza.download('tr')
nlp = stanza.Pipeline('tr')
# spaCy (Türkçe model)
# python -m spacy download tr_core_news_trf
import spacy
nlp = spacy.load('tr_core_news_trf')
Code language: PHP (php)3. Informal Metin Normalizasyonu
Sosyal medya ve ürün yorumlarında informal yazım yaygındır. Bu tür metinlerde Türkçe karakterlerin ASCII karşılıklarıyla yazılması, kısaltmalar, tekrarlayan karakterler ve argo kullanımı sıkça karşılaşılan sorunlardır.
def normalize_informal_turkish(text):
# Tekrarlayan karakterleri normalize et
text = re.sub(r'(.)\1{2,}', r'\1\1', text) # çoooook -> çook
# Yaygın kısaltmaları aç
abbrev_map = {
'slm': 'selam', 'mrb': 'merhaba', 'nbr': 'ne haber',
'tşk': 'teşekkür', 'öd': 'ödeme', 'kdv': 'katma değer vergisi'
}
words = text.split()
normalized = [abbrev_map.get(w.lower(), w) for w in words]
return ' '.join(normalized)
Code language: PHP (php)Uçtan Uca Preprocessing Pipeline
Tüm adımları bir araya getiren modüler bir pipeline örneği:
from dataclasses import dataclass
from typing import List, Callable, Optional
import re
@dataclass
class PreprocessingConfig:
lowercase: bool = True
remove_urls: bool = True
remove_html: bool = True
remove_stopwords: bool = True
lemmatize: bool = False
min_token_length: int = 2
remove_numbers: bool = True
normalize_turkish: bool = False
class NLPPreprocessor:
def __init__(self, config: PreprocessingConfig, stopwords: set = None):
self.config = config
self.stopwords = stopwords or set()
self.pipeline: List[Callable] = self._build_pipeline()
def _build_pipeline(self) -> List[Callable]:
steps = []
if self.config.remove_html:
steps.append(self._remove_html)
if self.config.remove_urls:
steps.append(self._remove_urls)
if self.config.lowercase:
steps.append(str.lower)
if self.config.remove_numbers:
steps.append(self._remove_numbers)
steps.append(self._normalize_whitespace)
return steps
def _remove_html(self, text: str) -> str:
return BeautifulSoup(text, 'html.parser').get_text()
def _remove_urls(self, text: str) -> str:
return re.sub(r'https?://\S+|www\.\S+', '', text)
def _remove_numbers(self, text: str) -> str:
return re.sub(r'\d+', '', text)
def _normalize_whitespace(self, text: str) -> str:
return re.sub(r'\s+', ' ', text).strip()
def preprocess(self, text: str) -> str:
for step in self.pipeline:
text = step(text)
return text
def tokenize(self, text: str) -> List[str]:
text = self.preprocess(text)
tokens = re.findall(r'\w+', text, re.UNICODE)
if self.config.remove_stopwords:
tokens = [t for t in tokens if t not in self.stopwords]
if self.config.min_token_length > 1:
tokens = [t for t in tokens if len(t) >= self.config.min_token_length]
return tokens
# Kullanım örneği
config = PreprocessingConfig(
lowercase=True,
remove_stopwords=True,
remove_urls=True,
min_token_length=2
)
preprocessor = NLPPreprocessor(config, stopwords=turkish_stopwords)
text = "Bu ürünü https://example.com adresinden aldım. Çok memnunum! 5 yıldız."
tokens = preprocessor.tokenize(text)
# ['ürünü', 'adresinden', 'aldım', 'çok', 'memnunum', 'yıldız']
Code language: CSS (css)Sonuç ve En İyi Pratikler
NLP preprocessing, projenin başarısını doğrudan etkileyen kritik bir aşamadır. Şu prensipleri aklınızda tutmanızı öneririm:
Görev odaklı düşünün. Her preprocessing adımı için “Bu adım görevime nasıl katkı sağlıyor?” sorusunu sorun. Gereksiz adımlar bilgi kaybına yol açabilir.
Deneysel yaklaşın. Farklı preprocessing stratejilerini karşılaştırın. Bazen minimal preprocessing en iyi sonucu verir.
Veriyi tanıyın. Preprocessing kararları veri kaynağına göre şekillenmelidir. Akademik metin ile sosyal medya verisi farklı yaklaşımlar gerektirir.
Modern araçları değerlendirin. Transformer tabanlı modeller kullanıyorsanız, kapsamlı preprocessing genellikle gereksizdir. Model’in pre-training sırasında öğrendiği bilgileri koruyun.
Pipeline’ı modüler tutun. Tekrar kullanılabilir, test edilebilir preprocessing bileşenleri oluşturun.
NLP preprocessing sürekli evrim geçiren bir alan. Yeni model mimarileri, yeni preprocessing yaklaşımlarını beraberinde getiriyor. Önemli olan, temelleri sağlam kavramak ve güncel gelişmeleri takip etmektir.